
Groq has recently emerged as a star in the AI chip industry, with claims that it is faster than Nvidia's GPUs. On March 2nd, it was reported that Groq acquired Definitive Intelligence, an artificial intelligence solutions company. This is Groq's second acquisition following the acquisition of Maxeler Technologies, a high-performance computing and artificial intelligence infrastructure solutions company, in 2022. Groq is making a strong entry into the market.
Since the explosion of ChatGPT, Nvidia has dominated the market with its GPUs, facing few challengers that can match its performance, but none as noteworthy as Groq.
Founded in 2016, Groq's founder is Jonathan Ross, a former Google employee known as the "father of TPU". The team includes former employees from Google, Amazon, and Apple. They have developed a Language Processing Unit (LPU) inference engine with a simple design. It is this LPU chip that has made Groq stand out in the AI market, attracting widespread attention. It is reported that the LPU can demonstrate very fast inference speed in today's popular Large Language Models (LLMs), significantly outperforming GPUs. The AI inference market should not be underestimated; in the fourth quarter of 2023, 40% of Nvidia's revenue came from this area. Therefore, many of Nvidia's challengers are entering from the inference side.
Advertisement
So, how does it achieve such speed? Why can it challenge Nvidia? What are the notable aspects of its chip architecture and technical path? Many people are curious about the mysteries behind this widely discussed chip. Recently, Semiconductor Industry Observation had the opportunity to interview Professor Sun Guangyu, a tenured associate professor at the Institute of Integrated Circuits at Peking University. Professor Sun provided some professional insights for us. As for the various online speculations about Groq's pricing, which are more complex than performance estimates, this article will not delve too much into them, but will focus on technical analysis to provide some inspiration for readers.
The fastest inference speed?
We live in a fast-paced world where people are accustomed to quickly obtaining information and meeting their needs. Studies have shown that when web page delays are between 300-500 milliseconds (ms), user stickiness drops by about 20%. This is even more evident in the era of AI. Speed is the top priority for most artificial intelligence applications. Large language models (LLMs) like ChatGPT and other generative AI applications have the potential to change the market and address major challenges, but only if they are fast enough and of high quality, meaning the results must be accurate.
To be fast, one must have strong computing and data processing capabilities. According to Groq's white paper [Inference Speed Is the Key To Unleashing AI's Potential] [1], when measuring the speed of AI workloads, two indicators need to be considered:
Output Token Throughput (tokens/s): The average number of output tokens returned per second, which is particularly important for applications requiring high throughput (such as summarization and translation) and facilitates comparison across different models and providers.
Time to First Token (TTFT): The time required for an LLM to return the first token, which is particularly important for streaming applications requiring low latency (such as chatbots).
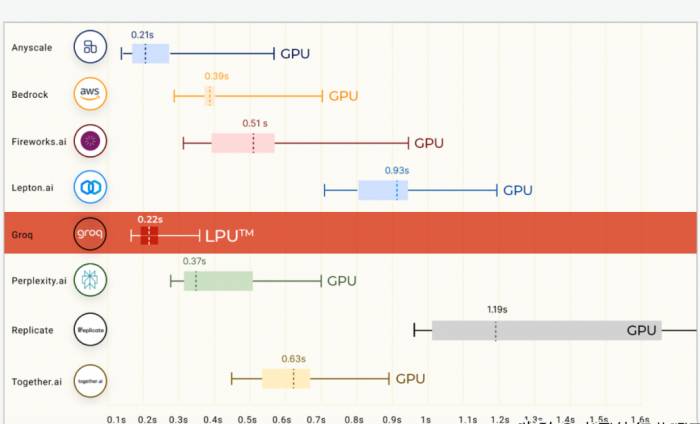
2) The two biggest factors affecting model quality are model size (number of parameters) and sequence length (the maximum size of the input query). Model size can be considered a search space: the larger the space, the better the results. For example, a 70B parameter model will generally produce better answers than a 7B parameter model. Sequence length is similar to context. A larger sequence length means more information - more context - can be input into the model, leading to more relevant and related responses.On Anyscale's LLMPerf leaderboard (which is a benchmark for evaluating the performance, reliability, and efficiency of large language model (LLM) inference providers), Groq LPU has achieved tremendous success in its first public benchmark test. The Llama2 70B from Meta AI, running on the Groq LPU inference engine, achieved an average result of 185 tokens/s in output token throughput, which is 3 to 18 times faster than other cloud-based inference providers. For the first token return time (TTFT), Groq reached 0.22 seconds. All Llama 2 computations were completed in FP16.
Output token throughput (tokens/s)
First token return time
How is this achieved?
Mining the "determinism" in the deep learning application processing process
Nowadays, a common consensus in the industry is that NVIDIA's success is not only due to its GPU hardware but also its CUDA software ecosystem. CUDA is also known in the industry as its "moat." So, how should other AI chip players compete with NVIDIA?
Professor Sun said that, indeed, CUDA provides an efficient programming framework for GPU developers, making it convenient for programmers to quickly implement various operators. However, relying solely on the programming framework cannot achieve high-performance operator processing. Therefore, NVIDIA has a large number of software development teams and operator optimization teams, who improve the computational efficiency of applications such as deep learning by carefully optimizing the underlying code and providing corresponding computational libraries. Due to the good ecosystem of CUDA, the open-source community has also made a considerable contribution.
However, the tight coupling of the CUDA framework and the GPU hardware architecture also brings challenges. For example, data interaction between GPUs usually requires global memory, which may lead to a large number of memory accesses, thereby affecting performance. If you need to reduce this type of memory access, you need to use technologies such as Kernel Fusion. In fact, NVIDIA has added SM-SM on-chip transfer paths in the H100 to achieve data reuse between SMs and reduce the number of memory accesses, but this usually needs to be manually completed by programmers, which also increases the difficulty of performance optimization. In addition, the entire software stack of GPUs was not originally designed specifically for deep learning. While providing versatility, it also introduces a significant overhead, which has also been studied in the academic community.Thus, this provides opportunities for new challengers in AI chips, such as Groq. For instance, Groq is exploring the "determinism" in the processing of deep learning applications to reduce hardware overhead and processing latency. This is also a distinctive feature of Groq's chips.
Professor Sun told the author that the challenge of realizing such a chip is multifaceted. One of the key challenges is how to achieve collaborative design and optimization between hardware and software to fully exploit "determinism" and achieve Strong Scaling at the system level. To achieve this goal, Groq has designed a dataflow architecture based on "deterministic scheduling." In terms of hardware, to eliminate "uncertainty," customization has been made in computation, memory access, and interconnect architecture, and some issues that are difficult to handle in hardware are exposed to software through specific interfaces for resolution. On the software side, it is necessary to leverage the characteristics of the hardware, combine with the upper-level application for optimization, and also consider usability, compatibility, and scalability, etc. These requirements pose many new challenges to the supporting toolchain and system level. If it relies entirely on manual tuning, the workload is substantial, and more innovation is needed at the tool level, such as compilers, which is a common issue faced by emerging AI chip companies (including Tenstorrent, Graphcore, Cerebras, etc.).
Is HBM the only solution? Challenging with pure SRAM.
The LPU inference engine mainly tackles the two bottlenecks of LLM - computational load and memory bandwidth. Groq LPU can compete with NVIDIA, and its pure SRAM solution plays a significant role.
Simplified LPU Architecture
Unlike the HBM solution used by NVIDIA GPUs, Groq has abandoned the traditional complex memory hierarchy, placing all data in on-chip SRAM, leveraging the high bandwidth of SRAM (80TB/s per chip), which can significantly enhance the bandwidth-limited (Memory Bound) parts in LLM inference, such as Decode Stage computation and KV cache memory access. SRAM itself is a necessary storage unit for computing chips, with GPUs and CPUs using SRAM to build on-chip high-speed caches, reducing slower DRAM accesses during the computation process as much as possible. However, due to the limited capacity of SRAM per chip, it involves hundreds of chips working together, which also involves the design of chip interconnects and algorithm deployment at the system level.
Groq mentioned that, due to the lack of external memory bandwidth bottlenecks, the LPU inference engine provides an order of magnitude better performance than graphics processors.
This pure SRAM architecture has been discussed in academia and industry in recent years, such as the University of Washington mentioned in the article [Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models], compared with DDR4 and HBM2e, SRAM has an order of magnitude advantage in terms of bandwidth and read energy consumption, thereby achieving a better TCO/Token design, as shown in the following figure. In the market, including Groq and other companies such as Tenstorrent, Graphcore, Cerebras, and domestic companies like PingTouGe Semiconductor (HanGuang 800), HouMo Intelligence (H30), etc., are trying to improve the efficiency of data interaction by increasing the capacity of on-chip SRAM and the ability of on-chip interconnects, thus seeking a competitive advantage in the field of AI processing chips that is different from NVIDIA.
Compared with DDR4 and HBM2e, SRAM has an order of magnitude advantage in terms of bandwidth and read energy consumption, thereby achieving a better TCO/Token design.Where lies the advantage of a pure SRAM architecture? Professor Sun points out that it mainly covers two aspects: The first aspect is that SRAM itself has the advantages of high bandwidth and low latency, which can significantly enhance the system's ability to handle memory-bound operators. On the other hand, due to the determinism of SRAM's read and write operations compared to DRAM, a pure SRAM architecture provides a foundation for deterministic scheduling in software. The compiler can arrange computing and memory access operations with fine granularity to maximize system performance. For GPUs, the HBM access latency can fluctuate, and the existence of cache levels also increases the uncertainty of memory access latency, adding to the difficulty of fine-grained optimization by the compiler.
It is well known that the HBM solution used by Nvidia GPUs faces the challenges of high cost, heat dissipation, and insufficient production capacity. So, what challenges does this pure SRAM architecture have?
Professor Sun analyzes: "The challenges of a pure SRAM architecture are also very obvious, mainly coming from the limitation of capacity. Chips like Groq were basically initiated and designed during the CNN era. For the models of this stage, a single chip with a hundred-megabyte SRAM as storage is sufficient. However, in the era of large models, since the model size can usually reach hundreds of GB, and the storage of KV-Cache (a key data structure) also occupies a lot of memory, the capacity of single-chip SRAM is obviously insufficient in the scenario of large models."
Taking Groq's solution as an example, in order to meet the inference requirements of a 70B model, it integrates 576 independent chips. Integrating so many chips also places very high demands on the bandwidth and latency between chips and nodes. A 576-chip cluster only has a 100GB SRAM capacity. The model needs to be divided through fine-grained pipeline parallelism (PP) and tensor parallelism (TP) to ensure that each chip's model partition is within 200MB. The cost of fine-grained division is a significant increase in the amount of data and overhead of inter-chip communication. Although Groq has also customized optimizations for interconnects to reduce latency, a simple estimate can find that the current inter-chip data transfer may also become a performance bottleneck.
On the other hand, due to the limitation of capacity, the storage space left for activation values during inference is very limited. Especially now, LLM inference needs to save KV-Cache, which is data that grows linearly with the length of input and output. Usually, for a 70B model, even with special techniques for KV-Cache compression (GQA), a 32K context length needs to reserve about 10GB of KV-Cache for each request, which means that the maximum number of requests that can be processed simultaneously in the 32K scenario is only 3. For Groq, due to the dependence on pipeline parallelism (TP), at least as many requests as the number of pipeline levels are needed to ensure that the system has a high utilization rate. A lower concurrency will significantly reduce the system's resource utilization rate. Therefore, if future long-context (Long-Context) application scenarios, in 100K or even longer contexts, the concurrency that pure SRAM architecture can support will be very limited. From another perspective, for edge scenarios, if more aggressive MQA and lower quantization bits are adopted, it may make the SRAM architecture more suitable.
If chips like Groq can indeed find suitable application scenarios, it should make algorithm practitioners more actively explore model compression, KV-Cache compression, and other algorithms to alleviate the capacity bottleneck of pure SRAM architecture. Some algorithms and applications with strong demands for inference latency, such as AutoGPT, various Agent algorithms, etc., the entire algorithm process needs to be processed in a chain of inference requests, which is more likely to achieve real-time processing and meet the needs of human interaction with the real world.
Therefore, in Professor Sun's view, whether to adopt pure SRAM or HBM is closely related to the development of future models and application scenarios. For data centers that use larger batch sizes, longer sequence lengths, and pursue throughput, large-capacity storage like HBM should be more suitable. For the edge side such as robots and autonomous driving, the batch is usually 1, the sequence length is limited, and the pursuit of latency, especially considering that the model has the opportunity to continue to be compressed, the scenario of pure SRAM should have a greater opportunity. In addition, it is also possible to look forward to the development of some new storage media, whether it can break through the on-chip storage capacity from hundreds of MB to the scale of GB.
Addressing the "Storage Wall" Challenge: Chip Architecture Innovation is Imperative
In fact, in addition to the aforementioned pure SRAM solution, in order to address the "storage wall" problem faced by the current von Neumann architecture, the industry is exploring a variety of new architectures, including in-memory computing and near-memory computing. These explorations cover traditional SRAM, DRAM, and emerging non-volatile storage technologies such as RRAM, STTRAM, etc., and there is extensive research being conducted. In the scenario of processing large models, there are also related innovative attempts, such as the DRAM near-memory computing architecture that Samsung, Hynix, and other companies are actively developing, which can provide a good trade-off between bandwidth and capacity, and also provides good opportunities for memory-intensive KV cache and small-batch Decode processing parts. (For those interested in this part, you can refer to the article "Unleashing the Potential of PIM: Accelerating Large Batched Inference of Transformer-Based Generative Models" on the processing of KV cache, which is a research direction that Professor Sun's team pays more attention to.)
In addition, from a broader perspective, no matter which storage medium is used, no matter whether it is in-memory or near-memory architecture, its essence and starting point are similar to Groq, which is to tap the internal high bandwidth of the storage architecture to alleviate the memory access bottleneck. If the demand for large capacity is considered at the same time, it is necessary to divide the storage, and then equip with a certain computing unit near (near-memory) or within (in-memory) the storage array. When the number of such divisions reaches a certain amount, it will even break through the boundaries of a single chip, and it is necessary to consider the interconnection issues between chips. For this type of architecture where computing and storage move from centralized to distributed, Professor Sun's team also habitually refers to it as a spatial computing (Spatial Computing) architecture. In short, the position of each computing or storage unit affects the task it undertakes. On the one hand, at the chip level, this distributed computing architecture is different from the abstraction provided by GPUs; on the other hand, when the scale expands to the level of multiple chips/cards, the problems faced are similar.In summary, large models indeed pose a significant challenge to traditional chip architectures, compelling chip practitioners to exercise their initiative and seek breakthroughs through "alternative approaches." It is noteworthy that a number of innovative chip enterprises in China have successively launched products with computing-in-memory or near-memory computing, such as Zhi Cun Technology, Hou Mo Intelligence, Ling Xi Technology, and so on.
Considering that the development cycle of a chip typically spans several years, Professor Sun believes that when trying new technologies, it is necessary to make a reasonable prediction of the development trends of future applications (such as LLM technology). By analyzing the development trends of applications and designing both hardware and software with a certain degree of flexibility and generality, the long-term applicability of the technology can be better ensured.
Post a comment