
According to incomplete statistics, the semiconductor industry has currently developed about 1000 packaging types, which are divided into interconnection types, including wire bonding, flip-chip, wafer-level packaging (WLP), and through-silicon vias (TSV), etc. Countless dies are interconnected through interconnection devices, forming the increasingly prosperous packaging market today.
Among them, advanced packaging has become the most concerned and popular field in the past two years. The slower the progress of advanced processes, the more prominent its importance is. Traditional "three major" companies such as AMD, Intel, and Nvidia have all entered the field, transitioning from 2D packaging to 2.5D packaging, and even challenging the peak of 3D packaging.
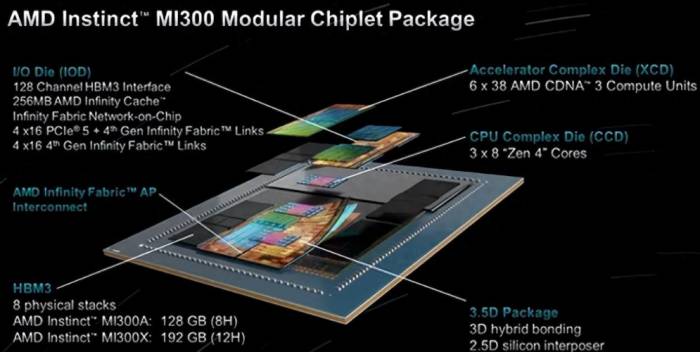
In June 2023, AMD officially launched the MI300X and MI300A AI accelerators in San Francisco. The MI300X uses 8 XCDs, 4 I/O dies, 8 HBM3 stacks, up to 256MB of AMD Infinity Cache, and a 3.5D packaging design, supporting new mathematical formats such as FP8 and sparsity. It is a design entirely aimed at AI and HPC workloads, and its transistors have reached 153 billion, becoming the largest chip ever manufactured by AMD.
AMD stated that the MI300X's performance in AI inference workloads is 1.6 times higher than Nvidia's H100, and its performance in training work is comparable to the H100, thus providing the industry with a much-needed high-performance alternative to replace Nvidia's GPU. In addition, the HBM3 memory capacity of these accelerators is also more than twice that of Nvidia's GPU, reaching an astonishing 192 GB, enabling the MI300X platform to support twice as many LLMs per system and run larger models than the H100 HGX.
Advertisement
The most eye-catching, of course, is the 3.5D packaging claimed by AMD. AMD stated that by introducing 3D hybrid bonding and 2.5D silicon interposer, a new "3.5D packaging" technology has been achieved.
Sam Naffziger, Senior Vice President and Corporate Fellow at AMD, said: "This is a truly amazing silicon stack, providing the highest density performance known in the industry to date. This integration uses two technologies from TSMC, namely SoIC (System on Integrated Chip) and CoWoS (Chip on Wafer on Substrate). The former (SoIC) uses hybrid bonding technology to stack smaller chips on top of larger chips, directly connecting the copper pads on each chip without solder, helping the high-speed buffer storage V-Cache chip to stack on the top CPU chip, while the latter (CoWoS) stacks chips on a larger silicon wafer, which is called an interposer, used to accommodate high-density interconnections."
While Nvidia is still using TSMC's CoWoS 2.5D packaging in the H200, AMD has taken the lead and achieved the combination of TSMC's SoIC 3D packaging and CoWoS 2.5D packaging. Its earlier layout of Chiplet seems to have been fully prepared for this overtaking.
Building chips like building blocks
First, let's review the specific architecture of MI300X and MI300A. According to AMD's official explanation, the MI300 series uses TSMC's 3D hybrid bonding SoIC (Silicon on Integrated Circuit) technology to stack various computing elements on top of four underlying I/O chips in 3D, whether it is a CPU CCD (Core Compute Die) or a GPU XCD. Each I/O chip can accommodate two XCDs or three CCDs. Each CCD is the same as the CCD used in the existing EPYC chip, with each CCD having eight hyper-threaded Zen 4 cores. MI300A uses three CCDs and six XCDs, while MI300X uses eight XCDs.The so-called XCD is the chiplet in AMD's GPU responsible for computation. On the MI 300X, eight XCDs contain 304 CDNA 3 computing units, which means each computing unit includes 34 CUs. In contrast, the AMD MI 250X has 220 CUs, marking a significant leap.
The HBM stack uses a standard interposer of 2.5D packaging technology for connection, with each I/O chip containing a 32-channel HBM3 memory controller, hosting two out of eight HBM stacks, thus providing the device with a total of 128 16-bit memory channels. The MI300X uses a 12Hi HBM3 stack with a capacity of 192GB, while the MI300A uses an 8Hi stack with a capacity of 128GB.
Specifically, AMD's CPU CCD is bonded to the underlying I/O chip through 3D hybrid bonding, communicating via the GMI3 interface of standard 2.5D packaging. AMD has added a new through-silicon via (TSV) interface to bypass the GMI3 link, providing the TSV required for vertically stacked chips.
The 5nm XCD GPU chip signifies the full chipletization of AMD's GPU design, with XCD and IOD having hardware-assisted mechanisms to break down tasks into smaller parts, assign them, and keep them synchronized, reducing host system overhead. These units also have hardware-assisted cache coherence.
For this small step in the MI300 series packaging, AMD has prepared for many years, with the earliest origins dating back to 1965 when AMD engineers developed a design that breaks each large chip into smaller pieces based on the "chipset" concept.
In the CPU competition with Intel, the failure of the Bulldozer architecture put AMD in a precarious position, urgently needing a low-cost solution to compete with Intel's more advanced architecture. Zen was born, and the new generation of Ryzen processors adopted a chipset or MCM (multi-chip module) architecture, marking a complete transformation of the entire PC and chip manufacturing industry.
The first-generation Zen architecture was relatively simple, adopting an SoC design, with everything from the core to I/O and controllers on the same chip, while introducing the CCX concept, where CPU cores are divided into four-core units and combined using an infinite high-speed cache. Two four-core CCXs make up a chip, but the consumer level is still a single-chip design.
The situation with Zen+ remained essentially unchanged (using a more advanced node), but Zen 2 was a significant upgrade, being the first consumer CPU design based on chiplets, with two computing chips or CCDs plus an I/O chip. AMD added a second CCD to the Ryzen 9, with an unprecedented number of cores in the consumer field.
Zen 3 further refined the chiplet design, eliminating the CCX and merging eight cores and 32MB cache into a unified CCD, greatly reducing cache latency and simplifying the memory subsystem. For the first time, AMD's Ryzen processors provided better gaming performance than their rivals, Intel. Zen 4 did not make significant changes to the CCD design, except for scaling down the CCD design.In the EPYC series, the first generation of AMD EPYC processors is based on four replicated chiplets. Each processor has 8 "Zen" CPU cores, 2 DDR4 memory channels, and 32 PCIe channels. To meet performance goals, AMD had to provide some additional space for the Infinity Fabric interconnect between the four chiplets.
The first chiplet of the second-generation EPYC is called the I/O die (IOD), which is made using a 12nm process and includes 8 DDR4 memory channels, 128 PCIe gen4 I/O channels, and other I/Os (such as USB and SATA, SoC data structures, and other system-level functions). The second chiplet is the complex core die (CCD), which is made using a 7nm process. In actual products, AMD assembles one IOD with up to 8 CCDs, with each CCD providing 8 Zen 2 CPU cores, thus providing 64 cores at once.
In the third-generation EPYC, AMD offers up to 64 cores and 128 threads using the latest Zen 3 cores. The processor is designed with eight chiplets, each with eight cores. This time, all eight cores in the chiplet are connected, achieving an effective dual L3 cache design for a lower overall cache latency structure.
In the fourth-generation EPYC, AMD uses up to 12 5-nanometer complex core chiplets (CCD) in the chiplet design, with the I/O chip made using a 6nm process technology, and the surrounding CCDs using a 5nm process. Each chip has 32MB of L3 cache and 1MB of L2 cache.
These CPUs ultimately paved the way for the technical aspects of the MI300 series chiplets.
In January 2021, AMD applied for and obtained a patent for an MCM GPU Chiplet design. AMD publicly disclosed a patent titled "GPU Chiplets with High Bandwidth Crossbar" at the United States Patent and Trademark Office, with the patent number "US 2020/0409859 A1". In the patent description, AMD outlined the future of the graphics chip in the Chiplet design, where the GPU Chiplet should communicate directly with the CPU, and other small chiplets communicate with each other through passive, high-bandwidth crossbar links, and are arranged as a system on chip (SoC) on the corresponding interposer.
In November 2023, AMD publicly disclosed another patent on Chiplet design, which described a completely different GPU design from the existing chip layout, that is, a large number of memory cache chips (MCD) distributed around the large main GPU chip. It described a system for distributing geometric workloads to multiple chips, all working in parallel. In addition, there is no "central chip" that assigns work to subordinate chips because they will all operate independently. The patent indicates that AMD is exploring the use of chiplets to manufacture GCD, not just a huge silicon wafer.
From the consumer field to the supercomputing field, and then to the AI field, AMD has set off a red storm with Chiplet, and the continuous driving force for this storm is the advanced packaging technology from TSMC.
The person behind AMD
In an interview with IEEE Spectrum, AMD product technical architect Sam Naffziger said: "Five or six years ago, we started developing the EPYC and Ryzen CPU series. At that time, we conducted extensive research to find the most suitable packaging technology for connecting chips. This is a complex equation involving cost, performance, bandwidth density, power consumption, and manufacturing capabilities. It is relatively easy to come up with a good packaging technology, but to truly produce it in large quantities and at low cost is another matter entirely."In 2011, TSMC (Taiwan Semiconductor Manufacturing Company) first developed the 2.5D packaging technology known as CoWoS (Chip on Wafer on Substrate), which was immediately adopted by Xilinx for its high-end FPGAs. However, due to its high cost, it struggled to gain a foothold in the packaging market. It wasn't until the global AI wave swept across the industry that companies like Nvidia, AMD, Google, and Intel extended their olive branches, propelling CoWoS to the throne of the most popular advanced packaging technology.
Below is a schematic diagram of TSMC's CoWoS packaging. CoWoS allows for the integration of multiple chips or dies on a single package. This enables the integration of different types of chips (such as processors, memory, and graphics chips) into a single package, thereby improving performance, reducing power consumption, and shrinking the form factor. Multiple chips are vertically stacked through silicon through-silicon vias (TSVs) and interconnected with microbumps. Compared to traditional 2D packaging, this stacking method can shorten interconnect lengths, reduce power consumption, and enhance signal integrity.
CoWoS has made significant contributions to AMD's Chiplet technology. By dividing large monolithic chips into smaller chiplets, designers can focus on optimizing the specific functions of each chiplet. This can achieve better power management, higher clock speeds, and higher performance per watt, while also helping to integrate these high-performance chips with other components such as memory into a single package, further enhancing system performance.
CoWoS has provided valuable experience for subsequent 3D packaging. In 2018, TSMC introduced SoIC (System on Integrated Chip) technology, an innovative multi-chip stacking technology mainly targeting wafer-level bonding for processes below 10nm. Compared to CoWoS technology, SoIC can offer higher packaging density, smaller bonding pitches, and can be used in conjunction with CoWoS/InFo to achieve multiple Chiplet integration.
At the IEDM conference, a TSMC vice president introduced more details of the company's SoIC roadmap. According to the roadmap, TSMC first adopted the currently available 9µm bonding pitch. Then, it plans to introduce 6µm pitch, followed by 4.5µm and 3µm. In other words, TSMC hopes to launch a new pitch every two years or so, with each generation's scaling ratio increasing by 70%.
He also used AMD's processors as an example of SoIC applications. AMD designed processors and SRAM based on the 7nm process, then handed them over to TSMC for production, and finally connected the chips with 9µm bonding pitch SoIC technology.
This is precisely the 3D V-Cache cache added to the EPYC processor codenamed Milan-X launched by AMD in 2021, which is also the world's first data center processor to adopt 3D chip stacking.
AMD stated that the 3D V-Cache adds an additional 64MB to the 32MB of SRAM on each computing chip of the current third-generation EPYC CPU, bringing the L3 cache of each computing chip in Milan-X to 96MB. Since the Milan-X processor architecture can have up to eight computing chips, the shared L3 cache in the CPU can reach up to 768MB. The additional L3 cache can alleviate memory bandwidth pressure and reduce latency, thereby significantly improving application performance.
The realization of this step is greatly attributed to TSMC's SoIC technology, which permanently binds the interconnects in the V-Cache to the CPU, reducing the distance between chips and achieving a communication bandwidth of 2TB/s. Compared to the 2D small chip packaging used by the third-generation EPYC CPU, the per-bit energy consumption of the interconnects in the Milan-X CPU is only one-third, the interconnect density is increased by 200 times, and the efficiency is improved by three times.This technology was later incorporated into the Ryzen 7 5800X3D processor, beginning to make a significant impact in the consumer market, including the latest Ryzen 9 7950X3D, which also utilizes the 3D V-Cache technology.
In 2023, TSMC (Taiwan Semiconductor Manufacturing Company) highlighted the new 3DFabric technology at the North American Technology Forum, which mainly consists of three parts: advanced packaging, 3D chip stacking, and design. Through advanced packaging, more processors and memory can be placed in a single package, thereby enhancing computational performance; in terms of design support, TSMC introduced the latest version of the open standard design language to assist chip designers in handling complex and large-scale chips.
From 2011 to 2023, TSMC's more than ten years of packaging technology evolution has finally realized AMD's Chiplet dream, and the MI300 series is also based on the latest 3DFabric, integrating TSMC's SoIC front-end technology with CoWoS back-end technology, which can be called the epitome of mass production of advanced packaging technology.
The packaging territory of the blue giant
For Intel, packaging is also one of the focuses of its development, and unlike AMD, Intel has chosen to develop its own packaging, striving to master the entire process of chip research and development, production, and application.
Intel's 2.5D packaging technology, which is comparable to TSMC's CoWoS, is called EMIB, which was officially applied to products in 2017, and Intel's data center processor Sapphire Rapids uses this technology; the first generation of 3D IC packaging is called Foveros, which was used in Intel's computer processor Lakefield in 2019.
The biggest feature of EMIB is to connect various chips such as memory (HBM) and computing through a silicon bridge (Silicon Bridge) from the bottom. Because the silicon bridge is buried in the substrate and connects the chips, allowing the memory and computing chips to be directly connected, it speeds up the chip's own energy efficiency.
Foveros is a 3D stack, stacking chips with different functions such as memory, computing, and architecture, and using copper wires to penetrate each layer to achieve connection. Finally, the factory will send the stacked chips to the packaging factory for assembly, connecting the copper wires with the circuits on the circuit board.
In 2022, Intel first integrated 2.5D and 3D packaging technologies together, named Co-EMIB, which is an innovative application that combines EMIB and Foveros technologies, allowing two or more Foveros elements to be interconnected, and basically achieving the performance level of a single chip. With this technology, the SoC with the largest number of transistors at the time—Ponte Vecchio, mainly targeting the high-performance computing market, was launched.
In fact, each Ponte Vecchio processor is a mirror set of two Chiplets connected by Intel Co-EMIB, and Co-EMIB forms a high-density interconnection bridge between the two 3D Chiplet stacks, which is a small piece of silicon embedded in the packaging organic substrate. The interconnection wires on the silicon can be narrower than those on the organic substrate. The normal connection interval between Ponte Vecchio and the packaging substrate is 100 micrometers, while the connection density in the Co-EMIB chip is almost twice that, and the Co-EMIB chip also connects the high-bandwidth memory (HBM) and Xe Link I/O Chiplet to the "base silicon" (the largest Chiplet), with other chips stacked on this "base silicon".The fundamental chip also utilizes Intel's 3D stacking technology, known as Foveros, which establishes a dense array of vertical chip-to-chip connections between two chips. These connections are only 36 microns apart and are achieved by "face-to-face" chip bonding; that is, the top of one chip is adhered to the top of another chip. Signals and power enter the stack through TSV (Through-Silicon Vias), which are rather wide vertical interconnections that directly penetrate most of the silicon. The Foveros technology used on Ponte Vecchio is an improvement over the technology used to manufacture Intel's Lakefield mobile processors, doubling the signal connection density.
Achieving this was not easy, according to Intel Fellow Wilfred Gomes, who stated that it required innovation in yield management, clock circuitry, thermal regulation, and power delivery. For instance, Intel engineers opted to provide the processor with a higher-than-normal voltage (1.8 volts) to reduce current and simplify packaging; the circuits in the substrate then step down the voltage to close to 0.7 volts for use on the computing chip, and each computing chip must have its own power domain within the substrate.
For Intel, Ponte Vecchio pushes its existing advanced packaging technology to the pinnacle, and it is not much inferior to AMD's MI300 series, making it a current red and blue star of advanced packaging.
In fact, although Intel is slightly behind TSMC in advanced process technology, it is on par with TSMC in advanced packaging. Intel stated that its flexible foundry services allow customers to mix and match its wafer manufacturing and packaging products. As an established manufacturer, its wafer packaging factories are scattered around the world, leveraging geographical advantages to expand capacity and services.
Intel CEO Pat Gelsinger also said in an interview that Intel has advanced capabilities in next-generation memory architecture, as well as the advantages of 3D stacking, which can be used for both Chiplet and large packaging for artificial intelligence and high-performance servers. In the future, we will apply these technologies to our products and also showcase them to customers of the Intel Foundry Services (IFS).
Why Chiplet?
After reviewing the technological journey of AMD, Intel, and TSMC, many people may have a question: why are they so committed to 3D packaging and Chiplet?
The reason stems from the internal needs of the semiconductor industry. The emergence of Moore's Law allows the continuously increasing device integration to continue to adapt to the same physical size. Photolithography shrinkage can reduce the building blocks by 30%, so it is possible to increase the circuit by 42% without increasing the chip size.
However, not all semiconductor devices can enjoy this dividend. For example, I/O that can include analog circuits has an expansion speed of about half that of logic, which forces people to look for new ways out. Moreover, the cost of photolithography shrinkage is not cheap. The cost of wafers processed with 7nm processes is higher than that of wafers processed with 14nm processes, the cost of 5nm processes is higher than that of 7nm processes, and so on... As wafer prices rise, Chiplet is often more economical than monolithic.In addition, due to the new chip design requiring design and engineering resources, and the increasing complexity of new nodes, the typical cost of new designs for each new process node also increases, which further motivates people to create reusable designs.
The chiplet design concept makes this possible, as new product configurations can be achieved by simply changing the number and combination of chips. By integrating individual small chips into 1, 2, 3, and 4 chip configurations, four different processor varieties can be created from a single wafer, whereas if they were to be integrated into a single chip, it would require four separate wafers.
AMD detailed why it had to adopt a chip set route for high-end graphics processors in its technical presentation on the new Radeon RX 7900 series "Navi 31" graphics processor.
In fact, over the past decade, AMD's Radeon GPUs have not been optimistic in terms of profit or revenue compared to CPUs, and the necessity to reduce manufacturing costs has become more prominent in the face of competition from NVIDIA. With the launch of the GeForce "Ada Lovelace" generation, NVIDIA continues to bet on single-chip silicon GPUs, and even the largest "AD102" chip is still a single-chip GPU, providing AMD with an opportunity to reduce GPU manufacturing costs.
Chiplets allow AMD to engage in price wars with NVIDIA and capture more market share. The most typical example is that AMD has adopted relatively aggressive pricing of $999 for the Radeon RX 7900 XTX and $899 for the RX 7900 XT. According to AMD's official website data, these two products have the ability to compete with NVIDIA's $1,199 RTX 4080, and in some cases, they may even be able to compete with the $1,599 RTX 4090.
In fact, this is one of the most significant advantages of chiplets. By using chiplets, AMD can quickly improve yield and simplify design/verification while selecting the best process for each small chip. The logic part can be manufactured using cutting-edge processes, large-capacity SRAM can be manufactured using processes around 7nm, and I/O and peripheral circuits can be manufactured using processes around 12nm or 28nm, thereby reducing design and manufacturing costs.
In addition, chiplets can also help it easily manufacture derivative types, such as the same logic but different peripheral circuits, or the same peripheral circuits but different logic, and it can mix and use small chips from different manufacturers, instead of being limited to a single manufacturer.
AMD is like this, and so is Intel. AMD relies on TSMC's existing technology and focuses on chip architecture design, while Intel has to work a little harder, studying advanced processes and packaging on one hand, and also starting to iterate and improve chips and chiplets on the other hand. The two companies even have a competition in packaging.
Nowadays, it is no longer important to judge the outcome of the competition, because 3D packaging and chiplets are gradually moving from data centers and AI accelerators to the consumer market's PC processors, ultimately benefiting notebooks and smartphones, and becoming a new trend recognized by everyone.In conclusion, compared to AMD and Intel, NVIDIA appears to be quite "sluggish" in 3D packaging and chiplets.
In June 2017, NVIDIA published a paper titled "MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability," which essentially proposed the MCM design, which can be seen as today's chiplet.
However, NVIDIA has not yet put this design into practice. Instead, in December 2021, it published a paper titled "GPU Domain Specialization via Composable On-Package Architecture," in which the proposed COPA-GPU architecture only separates the L2 cache, which means that NVIDIA will continue to adhere to the monolithic single-lithography design in the future.
The reason for NVIDIA's adherence to large chips is actually very simple: the communication bandwidth between dies can never be compared to the internal communication bandwidth of monolithic chips. Chiplets may not be suitable for high AI computing scenarios, but are more suitable for making great strides in the CPU field. In 2022, NVIDIA released the Grace CPU Superchip, which achieved high-speed chip interconnection through NVLink-C2C technology, and the chip also follows the chiplet interconnection specification UCIe jointly formulated by the industry.
NVIDIA's caution in chiplets has also made it less likely to be involved in 3D packaging. Although NVIDIA is currently one of the largest customers of TSMC's 2.5D packaging CoWoS, it is not yet included in the list of SoIC customers, making it the last of the three major companies to embrace this advanced technology.
With the rapid development of chiplets, NVIDIA may also start to embrace this design concept in the future. This year, the informant Kopite7kimi said that NVIDIA's next-generation Blackwell GB100 GPU for high-performance computing (HPC) and artificial intelligence (AI) customers will fully adopt the chiplet design.
Now, AMD has taken the lead in AI chips, using chiplets and 3.5D packaging to create larger and stronger MI300X. Intel has also fully embraced chiplets and 3D packaging. Although NVIDIA still has a vast AI market, its throne has a barely noticeable crack. Among these three companies, who can truly master the discourse in chip packaging?
Post a comment